Why L3 appchain boilerplates matter
Layer 3 (L3) appchains represent the next evolution in modular blockchain architecture. Unlike generic Layer 2 rollups that share a single execution environment, an L3 appchain provides a dedicated chain for a specific decentralized application. This separation allows developers to customize consensus mechanisms, gas tokens, and execution logic without compromising the security of the underlying Layer 2.
Boilerplates are the essential tool for this deployment. They abstract the complex infrastructure required to spin up a sovereign rollup, allowing teams to focus on application logic rather than chain maintenance.
The value lies in sovereignty. With a boilerplate, you control the block space, the sequencing rules, and the economic model. This is critical for dApps that require high throughput or specific privacy guarantees that cannot be achieved on shared L2 networks. The boilerplate handles the heavy lifting of connecting to the L2 settlement layer, ensuring your appchain remains secure while operating independently.
Select the right DevRel kit
A sovereign rollup is only as usable as its documentation and SDKs. Most boilerplates provide the smart contracts and sequencer logic, but skip the developer experience layer. You need a kit that includes generated API references, TypeScript client libraries, and community onboarding templates so your users can interact with your chain without reading your source code.
When evaluating a DevRel kit, check for three specific assets: a working frontend scaffold, an SDK that matches your chain’s language, and automated documentation generation. If the boilerplate requires you to write your own README or build your own SDK wrapper, it will delay your mainnet launch. The goal is to hand off a ready-to-deploy developer portal, not just a node binary.
Compare the top options side-by-side to see which fits your stack.
| Boilerplate | Primary Language | DevRel Assets | Settlement |
|---|---|---|---|
| L3 Boilerplate | Rust | Docs + SDK | Ethereum |
| Madara | Rust | Docs + SDK | Starknet |
| Sovereign SDK | Go | Docs Only | Ethereum |
| Axiom | TypeScript | Docs + SDK | Arbitrum |
Deploy your sovereign rollup
This section walks through the linear workflow for initializing and deploying a sovereign rollup using a modern boilerplate. We assume you have already selected a framework (such as a Rust-based SDK or a Spire-compatible stack) and have your local development environment configured.
The goal is to produce a fully functional L3 node that settles to an L2 layer, reads state synchronously, and exposes a sequencer endpoint for your application.
Begin by cloning your chosen repository. For most modular blockchain stacks, this involves pulling the base SDK and running an initialization script that generates the project structure.
Ensure you install the correct dependencies for your target chain (e.g., Ethereum L2, Optimism, or Arbitrum). If using a Rust-based stack, run cargo build to verify the toolchain. For JavaScript/TypeScript stacks, run npm install or yarn. This step creates the foundational files you will edit, including the genesis configuration and node entry points.
Define the genesis block in genesis.json or the equivalent configuration file. This file dictates the initial state of your L3, including the starting block height, the address of the L2 settlement contract, and the sequencer’s public key.
For a based L3 appchain, you must explicitly link the L2 settlement layer. This ensures your rollup can synchronously read data from the L2 in real-time, a critical feature for state verification. Update the RPC endpoints to point to your local L2 testnet or a public testnet node. Verify that the chain ID in your genesis file matches the target L2’s chain ID to prevent cross-chain replay attacks.

The sequencer is the heart of your sovereign rollup. It orders transactions and produces blocks before submitting state roots to the L2. Start the sequencer service using your boilerplate’s command-line interface.
Configure the sequencer to listen on a local port (e.g., localhost:8545) for testing. In a production environment, you would expose this via a load balancer. Ensure the sequencer has access to the L2 RPC node to fetch pending transactions and state roots. If the sequencer fails to sync, check your network permissions and L2 RPC connectivity.
Before going live, deploy your rollup to a testnet to validate the full pipeline. This includes testing transaction submission, block production, and state root commitment to the L2.
Use a testnet faucet to fund your sequencer’s operational wallet. Submit a few test transactions and monitor the L2 for the corresponding state root commitments. If the state roots are not appearing on the L2, verify that your sequencer is correctly signing the blocks and that the settlement contract address in your genesis file is accurate.

Final verification involves confirming that your L3 appchain is fully sovereign and operational. Check that your application can read data from the L3, that the sequencer is producing blocks at the expected interval, and that the L2 settlement layer is receiving state updates.
Run any provided integration tests in your boilerplate. If you are using a Spire-based stack, verify that the synchronous data reading from the L2 is functioning as expected. Once verified, you are ready to configure the production environment, which involves setting up persistent storage, securing the sequencer keys, and exposing the RPC endpoint to your users.
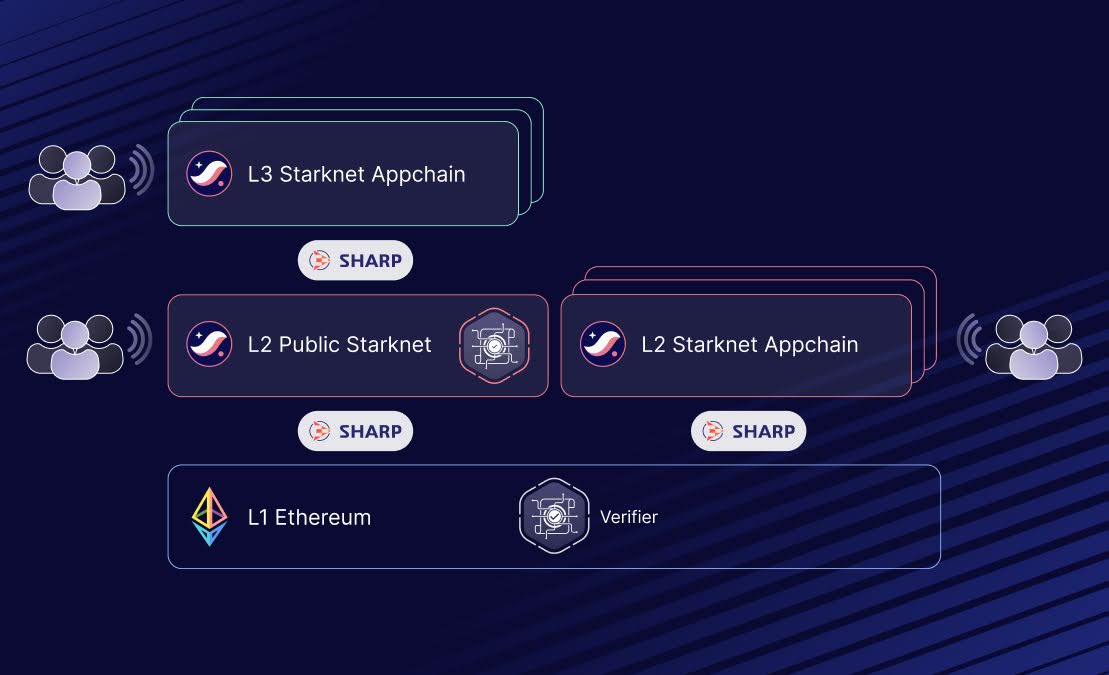
Connect Your L3 to an L2 Settlement Layer
Sovereignty means you control execution, but security comes from the settlement layer. Your L3 must post transaction data and state roots to an L2 like Base or Arbitrum. This process, known as data availability (DA), ensures that your chain’s history is immutable and verifiable by anyone. Without this connection, your L3 is just an isolated network with no cryptographic proof of its state.
1. Configure the Sequencer
The sequencer is the engine that orders transactions on your L3. You must configure it to forward batches of transaction data to the L2. This is not a manual upload; it is an automated process where the sequencer packages blocks into "batcher" transactions.
- Batch Size: Define the maximum number of transactions or time window for each batch. Larger batches reduce L2 gas costs but increase finality latency.
- Batcher URL: Point your sequencer’s output to the L2 batcher contract address. This ensures data lands on the L2 blockchain rather than just being stored locally.
2. Deploy the Fault Proof System
To maintain security guarantees similar to the L2, you need a dispute mechanism. Most modern L3 stacks use a Fault Proof system (like OP Stack’s fraud proofs or ZK proofs) to challenge invalid state transitions.
- Challenge Window: Set a time window (e.g., 7 days) during which anyone can submit a fraud proof if they detect an invalid state root.
- Bonding: Require operators to post a security bond on the L2. If a fraud proof is successful, the bond is slashed.
3. Verify Data Availability
Once your L3 is live, you must verify that data is actually being posted to the L2. If the sequencer goes offline or censors data, your L3 becomes unusable. Use a data availability monitor to track the latest batch submission on the L2.
- Monitor Block Height: Ensure the L2 block height is advancing.
- Check Batch Size: Confirm that the amount of data posted matches your L3’s throughput.
Common Pitfalls
- Ignoring Gas Costs: L2 gas prices fluctuate. If your L3 is too quiet, posting data might cost more than the fees you collect. Implement dynamic batching to adjust to gas conditions.
- Weak Sequencer Incentives: If sequencers are not paid enough to post data, they may stop. Ensure your fee market is robust enough to cover L2 data costs.
Verification Checklist
-
Sequencer is configured to send batches to the L2 batcher.
-
Fault proof system is deployed and challenge window is set.
-
Data availability monitor is active and reporting L2 batch submissions.
-
Security bond is posted on the L2.
Verify chain health and metrics
Once the sovereign rollup is live, you need to confirm it is syncing data from the L2 settlement layer correctly. This verification ensures your L3 appchain is functioning as a true based chain, synchronously reading L2 state rather than relying on asynchronous or delayed data feeds.
Run the following checks to validate the chain's health and data integrity:

Send a eth_blockNumber request to your L3 RPC. A healthy chain responds with a monotonically increasing block number. If the node is unresponsive or returns stale data, verify your RPC provider configuration and network connectivity.
Confirm the L3 block height is advancing in step with the L2 settlement layer. Use the Spire docs or your boilerplate's health endpoint to check the l2_block_height vs l3_block_height. The demo shows a based L3 appchain synchronously reading data from its L2 settlement layer in real-time, so this delta should remain minimal.
Submit a test transaction on the L3 and monitor its inclusion. Check that the transaction is included in an L3 block and that the state root is correctly posted to the L2. This proves the sovereign rollup is processing transactions and settling them securely.
-
RPC endpoint responds to eth_blockNumber
-
L3 block height tracks L2 settlement layer
-
Test transaction included and settled on L2
-
State root posted correctly to L2
Common L3 deployment mistakes
Boilerplates accelerate sovereign rollup launches, but default configurations rarely survive mainnet stress. Misconfigured gas limits and incorrect sequencer settings are the most frequent points of failure. These errors often stem from treating a template as a finished product rather than a starting point.
Misconfigured gas limits
Gas limits must reflect your specific transaction throughput. Default values often assume low volume. If your L3 appchain processes more data than the block size allows, the sequencer will drop transactions or halt. Verify your gas limit against your expected peak load during testnet runs.
Incorrect sequencer settings
The sequencer is the heart of your modular blockchain. If the sequencer is not properly configured to submit data to the underlying L2, your chain becomes isolated. Ensure the sequencer’s output submission interval matches your L2’s data availability constraints. A mismatch here breaks the settlement layer entirely.
Ignoring fault proof configurations
Sovereign rollups require clear fault proof mechanisms. Boilerplates often leave these as placeholders. If you do not explicitly define how disputes are resolved, your chain lacks security guarantees. Test the fault proof logic before deploying to mainnet to ensure your sovereign status is technically valid.
No comments yet. Be the first to share your thoughts!